
jeu, 05/04/2018 - 14:14
Depuis quatre ans ou moins, la majorité des entreprises a pris le virage de la data. Les entreprises deviennent des « Data Driven company ». Et cette prise de conscience se traduit par la nécessité de revoir les process et les architectures orientées autour des données.
Depuis longtemps, les pays Anglo-Saxons mesure la maturité d’une entreprise par sa capacité à gouverner ses processus au travers des données (Via le référentiel COBIT de l’ISACA par exemple).
Auparavant, les entreprises pouvaient atteindre l’excellence par le niveau Optimisé. Aujourd’hui, les sociétés Data Driven visent un niveau supérieur : l’Evolutifs. Leur Business Model se veut évolutif, prédictif et prospectif. Comment ? en intégrant l’IA et le Cognitif dans les processus, en exposant et monétisant la donnée. Il s’agit d’utiliser au mieux le patrimoine Data de l’entreprise et sa capacité à aller chercher de nouvelles données pour améliorer ses processus.

Dans cette démarche DataDriven, le choix de l’architecture de données est capital pour répondre à des objectifs à court et long termes afin de garantir la trajectoire vers un objectif de maturité.
Comment bien définir les usages actuels et se projeter sur les usages futurs pour la pérennité du modèle ?

Répondre à un panel d’usages et de pratiques – tel que définis ci-dessus – correspond à la mise en œuvre d’une architecture de type micro-services. Ce n’est pas une seule typologie de base de données, mais bien plusieurs qui permettent de répondre à un ensemble de pratiques.
Tout d’abord, il faut être en capacité de définir sa Stratégie Data - qui reflète et suit la stratégie de l’entreprise, en menant les actions suivantes :
- Traduire les objectifs en usages : identifier la valeur apportée au travers de la donnée et de l’usage,
- Traduire les usages en briques d’architectures et leurs évolutivités dans le temps,
- Identifier les données nécessaires : celles du patrimoine de l’entreprise et celles de l’extérieur en capacité d’apporter de la valeur,
- Choisir les solutions optimales : les types de bases de données en fonctions des usages et des données identifiées,
- Identifier les impacts organisationnels et les nouvelles fonctions,
- Mettre en place une stratégie pour la gouvernance et la protection des données.
C’est uniquement dans cette logique là que doivent s’opérer les bons choix en termes d’architectures de données, de typologie de bases de données (orientée texte, hiérarchique, graphique, réseau, relationnelle, objet…), et de choix de bases de données (solutions).
Comment définir son architecture de données ?
Force est de constater qu’un seul type de SGBD ne répond pas à l’ensemble des usages. Dans une architecture orientée Data Driven, cinq zones doivent être établies pour prendre en charge tous les besoins.
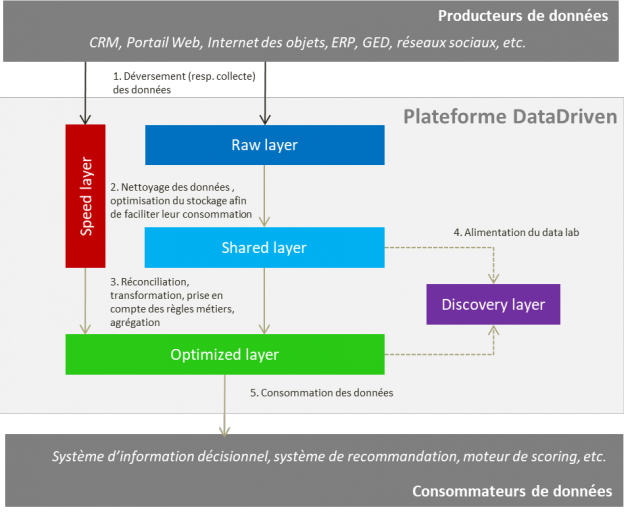
Raw layer : Zone où toutes les données collectées sont déversées avant leur intégration. Le tout, en mettant en place une certaine logique de tri et d’organisation de ces données.
Shared layer : Zone où toutes les données collectées sont stockées après leur nettoyage et optimisation de leur stockage en vue de leur exploitation
Speed layer : Zone de traitement de données en temps réel.
Optimized layer (Exposition): Zone de dépôt de données après prise en compte des règles métiers. L’accès, le stockage et le format des données sont optimisées pour faciliter la consommation des données
Discovery layer (Exploration) : Cette zone répond au besoin d’exploration ou de découverte des données. Elle représente une sorte d'emplacement où des bacs à sable peuvent être créés afin de tirer parti des capacités de calcul de la zone.
Afin de répondre à ces architectures de données, il existe différentes typologies de bases de données :
- La plate-forme Hadoop - HDFS
Hadoop est un Framework libre et écrit en Java qui contient un panel d’applicatifs liés aux traitements et bases de données. Le niveau de base d’une plate-forme Hadoop est le système HDFS (Hadoop Distributed File System). Le système de gestion de fichiers distribués permet de stocker les données sur les machines du cluster. Ce système permet de constituer en général un niveau de stockage basique (RawData dans l’architecture de données) pour y stocker des données en masse non transformées et historisées.
Principales solutions : Cloudera CDH (Cloudera’s Distribution including Apache Hadoop), Hortonworks HDP (Hortonworks Data Platform), MapR, Pivotal (Pivotal Big Data Suite).
- Les bases de données NoSQL
- Clé-Valeur : Ces bases de données sont ultra-rapides et simplifiées. Elles permettent une représentation simple, d’indexer des données diverses via une clé et s’adaptent à la gestion des caches ou l’accès rapide à l’information. A noter que seulement trois opérations sont possibles : le « Put » pour donner une valeur à une clé, le « Get » pour récupérer la valeur d'une clé et le « Delete » pour effacer la clé et sa valeur. Parfois, la notion de bucket ou couplage se fait par un moteur d'indexation (ex : Riak). Enfin, le taux de performance est très élevé avec le in-memory possible.
Les outils : AmazonDynamoDB, Redis, Riak …
A utiliser pour :
- Des données très volatiles
- Session utilisateur, données d'un panier d'achat
- Des données très peu volatiles et accédées très fréquemment
- Descriptions produits, paramétrage applicatif
A éviter pour :
- Des données possédant des relations
- Relations entre agrégats entre les données de différents ensembles de clés
- Des opérations impliquant de multiples clés
- Des besoins de requêtage
Le NoSQL peut traiter différents types de données. Ces bases de données comptent différentes catégorisations pour répondre aux nombreux besoins de stockage du Big data. Et chaque catégorie dispose de ses propres techniques de modélisation dont le document, la colonne et le graphe.
- Document : j’enregistre ce que je veux, comme je veux. La modélisation est souple et permet de stocker des documents au format JSON dans des collections, le stockage de masse. Il permet d’étendre le paradigme clef/valeur, avec des « documents » plus complexes à la place des données simples, et une clef unique pour chaque document. Ces bases de données comptent des documents de type JSON ou XML et permettent de stocker, extraire et gérer des documents (données semi-structurées) souvent regroupés par Collection. Elles intègrent également les fonctions d'agrégation : sum, count, group, etc.
Outils : MongoDB, CouchDB, entre autres.
A utiliser pour :
- Données avec partie structurée et partie non structurée ;
- Données de publication variables ;
- CMS, Blogging avec commentaires, contenu dynamique, etc.
A éviter pour :
- Opérations nécessitant consistance sur plusieurs agrégats ;
- Des structures d'agrégat très changeante avec des besoins de requêtage forts ;
- Inconvénient du Schemaless.
- Colonne : Ses points forts sont sa performance et sa consistance. Il s’agit d’une extension du système clé-valeur qui permet de stocker un grand nombre de données sur une même ligne, et du type one-to many. Ces bases de données permettent principalement d’avoir un accès instantané à une valeur (ou une ligne) dans une table qui peut avoir une taille de l’ordre de plusieurs milliards de lignes via une clé unique appelée « row key ». Les lignes stockées dans la table peuvent être de structure différentes, ce qui est connu sous le terme « Schemaless ». Malgré leur grande performance dans l’accès aux données, ces bases de données ne sont pas faites pour faire des requêtes sur les tables ni des traitements d’agrégation. Le seul moyen d’accéder à une donnée dans la table doit être fait par l’intermédiaire de la « row key ». Cette caractéristique donne une très grande importance au choix de la row key qui est considéré comme la partie cruciale sur laquelle repose toute la conception de la table. Cela est connu sous « Tables designed by query ».
Exemples de bases de données orientées colonne : HBASE, Cassandra, …
Ces bases de données sont à utiliser pour :
- Données avec partie structurée et partie non structurée
- Evénements des applicatifs (sharding possible par application)
- Données de publication variables
- Compteurs et analytiques
- Données avec TTL (Time To Leave)
A éviter pour :
- Des besoins de requêtage complexes
- Des besoins de calcul d'agrégation simples
- Graphe : Il analyse des relations et permet une modélisation optimisée pour les problèmes de graphes. Le stockage est provisoire afin de traiter des données de type réseaux (sociaux, électrique, …).
Outils : Neo4j, Titan, entre autres.
Basées sur les théories des graphes, elles s’appuient sur les notions de nœuds, de relations et des propriétés qui leur sont rattachées. Conçues pour les données dont les relations sont représentées comme graphes, et ayant des éléments interconnectés, avec un nombre indéterminé de relations entre elles, ces bases de données sont optimisées pour traverser le graphe rapidement dans n'importe quel sens. Par exemple, pour répondre à « Quelles sont les personnes employées par X dont les amis aiment le film Y ? ». En fin, elles s’adaptent aux traitements des données des réseaux sociaux.
A utiliser pour :
- Les moteurs de recommandations : « Les autres clients ayant acheté ce produit ont aussi acheté ... »
- Les données naturellement connectées (Réseaux sociaux)
- Les services basés sur la localisation ou le calcul d'itinéraires
A éviter pour :
- Opérations nécessitant consistance sur plusieurs agrégats
- Des structures d'agrégat très changeantes avec des besoins de requêtage forts
- Inconvénient du schemaless
- Les base de données SQL (relationnelle)
L'information est organisée dans des tableaux à deux dimensions appelés des relations ou tables. Selon ce modèle relationnel, une base de données consiste en une ou plusieurs relations. Les lignes de ces relations sont appelées des nuplets ou enregistrements et les colonnes, des attributs.
Outils : Oracle, SQL Server, IBM DB2, entre autres.
Ses points forts :
- Cohérence des données à travers le schéma des bases de données ce qui évite le risque de changer le schéma relationnel,
- Contraintes d'intégrité pour un gage de cohérence du contenu de la base de données,
- Fonctionnement transactionnel avec la gestion des transactions caractérisé par l'acronyme ACID (Atomicité, Cohérence, Isolation, Durabilité), qui garantit que soit toutes les opérations d'une transaction sont effectuées avec succès,
A utiliser pour :
- Les usages de reporting classiques, données préparées pour des solutions analytiques,
- Stockage d’objets métier dans une architecture de données (Optimized Layer)
- Agrégation et préparation des données pour un stockage sous forme de Datamart
A éviter pour :
- Le traitement de grosses volumétries sur des données de détail
- Des structures et modèles changeants
Afin de rentrer dans le concret, il s’agit maintenant de définir une architecture DataDriven répondant à des usages orientés autour du Client dans une logique retail.

Tout d’abord, il faut être capable dans ce contexte de créer une architecture en capacité de répondre à des usages analytiques de Haut Niveau :
- Le reporting opérationnel et d’entreprise,
- L’exploration & DataLab pour l’ouverture et l’exploration de la donnée aux Data Analyst et DataScientist,
- L’exposition de la donnée à des applications de type CRM, DMP afin d’être en capacité de proposer de la recommandation produit, client ou tarification en temps réel. Et voire même de pouvoir aller vers de la monétisation de la donnée auprès des partenaires.
Ensuite, une architecture de données et des composants permettant de garantir la capacité à répondre à ces usages est établie.

Une architecture de données mixte doit répondre à l’ensemble des usages.
Une architecture de type Hadoop favorise l’aspect Datalake / Datacentric, pour assurer le 1er niveau d’architecture de données (RawData) et permet un stockage massif des données.
Plusieurs typologies de bases sur le niveau Shared Data, Hive/Impala préparent, gèrent et requêtent des données stockées dans HDFS ou dans HBase avec une logique SQL. HBase traite le stockage et l’accès instantané à une donnée clé-valeur dans des tables qui peuvent être d’une taille de l’ordre de plusieurs milliards de lignes. Quant à MongoDB, il favorise la recherche sur les données non structurées de type documents (JSON ou XML) dans une logique schemaless. Le framework Spark, lui, permet les traitements liés à toutes ces bases pour un niveau de performance élevé.
La couche Discovery étant une image des éléments disponibles dans la couche Shared Layer est isolée dans une SandBox pour laisser libre court aux analyses et explorations des experts sur les Data et besoins autour des données.
La couche Optimized Layer est desservie par 2 typologies de bases : Hbase pour adresser les usages d’exposition des données au travers d’API et de WebServices ainsi qu’une base relationnelle permettant l’exposition des données préparées et agrégées pour les usages de Reporting.
Force est de constater qu’au travers de cet exemple l’utilisation de 5 typologies de SGBD permet de répondre à un ensemble d’usages de manière optimisée. Chaque SGBD répond à une demande particulière pour laquelle il est le plus performant, optimisé et évolutif (logique de Best Of breed).
Comment répondre à la domiciliation de son architecture ? Cloud, SaaS, On Premise, etc. Pourquoi choisir une Appliance ?
Le sujet de la domiciliation répond à une logique de politique d’entreprise, de protection des données et d’exigences en termes de niveaux de services.
Les Appliances répondent en priorité à cette logique d’engagement de services et de haut niveau de performance. Elles se positionnent sur la garantie d’un niveau de performance très élevé malgré de la volumétrie ou des traitements très consommateurs. Elles offrent également la promesse d’un niveau d’administration et configuration faible, à contrario des architectures Hadoop par exemple. Le point faible restera l’évolutivité de telles architectures face à une évolution croissante des besoins et usages.
On va retrouver des leaders tels qu’Oracle (Exadata, BigData Appliance), IBM (Netezza), Teradata, …
Les opérateurs Cloud offrent eux la promesse d’une architecture scalable, évolutive, voire même la possibilité d’externaliser l’exploitation de ces architectures. Ils sont idéaux pour un déploiement adapté de ces architectures. Leurs utilités ? Lancer une démarche de QuickWin autour de la donnée, prouver la valeur de ces démarches DataDriven autour de DataLab en traitant des 1ers UsesCases. Cela permet d’ouvrir les services et les usages au fur et à mesure de la trajectoire. Toutefois, on constate souvent une certaine frilosité justifiée ou non à faire confiance à ces opérateurs pour protéger et garantir ses données.
On va retrouver des leaders tels que Azure de Microsoft, Amazon WS, Google Cloud Platform, Orange Application for Business, entre autres.
Les déploiements On Premise se positionnent dans une démarche de maîtrise de ses environnements et de ses données. Il existe ainsi une volonté d’investir à la fois dans l’infrastructure, et les compétences en interne. Dans ce cadre, il y a une obligation d’avoir une vision claire sur la trajectoire à adopter et l’évolution de l’architecture dans le temps. Comme pour les appliances, on perdra en agilité mais avec une garantie de la maîtrise des données et une intégration complète dans l’architecture et les exigences de l’entreprise.
Il faut malgré tout retenir que dans une démarche efficiente ce ne sera pas l’un ou l’autre. Toutefois, ce pourra être l’un à la suite de l’autre. Dans une démarche d’approche QuickWin, toute entreprise peut se lancer dans des architectures Cloud agiles d’apprentissage et revenir ensuite à une architecture On Premise lorsque l’entreprise a atteint un niveau de maturité et ainsi poursuivre sa trajectoire Data.
Enfin, le choix d’une architecture de données ou d’une base de données n’est pas le simple choix d’un espace de stockage. Il doit s’intégrer dans une démarche Data Driven qui est une démarche orientée autour de l’architecture pour répondre à des enjeux d’entreprise.
Aujourd’hui, à l’heure de choisir une architecture de données, il faut être suffisamment à l’écoute de l’évolution des technologies et de l’apport de celles-ci. Une vérité ne sera vraie que quelques semaines, mais la démarche sera toujours la même en partant des usages et en identifiant les briques qui répondent le mieux à celui-ci.
Bien malin est celui qui va prédire tous les usages liés à la Data. En effet, nous sommes déjà dans le prédictif, le prescriptif, le temps réel et l’Intelligence Artificielle. Qui c’est si demain nous intégrerons en nous des bases de données avec de la bio technologie ou encore si nous repousserons la limite des architectures avec notre corps comme support.
A propos de l'auteur

Commentaires
C'est dommage que les illustrations soient trop petites et donc illisibles…
Vous avez tout à fait raison. Nous étions en attente de meilleurs visuels. Bonne lecture !