
Du prototypage Python à la mise en production d'applications analytiques en C/C++
Lorsque qu'une société, quel que soit son secteur d'activité, doit industrialiser (ou mettre en production) une application impliquant une partie calculatoire stratégique (algèbre linéire, optimisation, régression, prévisions, séries temporelles, datamining, statistiques avancées etc...), il est largement admis qu'une phase de prototypage est nécessaire voire indispensable en amont. En effet, cette phase de prototypage va permettre de rapidement tester différents scénarii et de valider les modèles ou les techniques mathématiques et statistiques qui seront privilégiés avant d'être mis en production.
Il apparait que pour la plus grande majorité de ces organisations, les outils d'analyse numérique utilisés lors de la phase de prototypage sont complètement différents de ceux utilisés par l'application finale. Ce choix est léitime puisque les exigences sont différentes de part et d'autre. En amont (phase de prototypage), on a besoin de développer rapidement, de pouvoir facilement basculer d'une hypothèse à une autre (pour mon cas, cet algorithme est-il plus approprié que celui-ci ?), d'importer et de visualiser un jeu de données sans avoir à écrire trop de lignes de code. En aval (mise en production), les exigences vont davantage être axées sur les performances de la partie calculatoire (vitesse d'exécution), sur sa robustesse (capacité à traiter des gros volumes de données et à gérer efficacement des problèmes de divergences numériques par exemple) et sa fiabilité (précision des résultats). Oui, il y a clairement un hiatus entre ces 2 mondes. La technique la plus naturelle pour passer d'un monde à l'autre consiste à recoder le prototype (au moins la partie analytique) dans le langage imposé par l'application finale. Mais n'y aurait-t-il pas une approche plus raisonnable, plus productive et plus sûre 'agissant de la partie analytique.
L'idée
Elle consiste à utiliser le même moteur de calculs pour le prototype et pour l'application finale.
Quels en sont les avantages ?
- Gain de temps: pas besoin de recoder cette partie stratégique en C/C++. La tâche étant particulièrement ardue puisque pour la très grande majorité des cas, les langages de prototypage sont peu explicites quant aux méthodes mathématiques et statistiques internes employées
- Forte diminution des risque: les résultats numériques seront strictement identiques entre le prototype et l’application de production. De fait, les erreurs d’implémentations ou de modèles numériques seront découvertes en phase amont – et pourront être traitées ou déboguées plus rapidement et plus facilement -, et non en phase d’industrialisation.
Intéressant. En ce cas, quel langage de prototypage utiliser ?
Python.
,Pourquoi Python ?
- Python rentre parfaitement dans le cadre d’un langage de prototypage. De plus, il existe de nombreux modules complémentaires fiables permettant au scientifique de travailler confortablement avec ses données (manipulation de tableaux, accès aux bases de données et fichiers, visualisation, construction d’IHM, plugin Eclipse etc…)
- Python est un langage de haut niveau, intuitif et facile à appréhender, même pour quelqu’un qui n’est pas spécialement informaticien ;
- Python n’est pas un langage propriétaire et est aujourd’hui un langage suffisamment mature et fiable ;
- Adoption croissante depuis plusieurs années déjà de Python par la communauté scientifique.
Certes. Et le socle commun « calcul mathématique et statistique en C/C++ » dans tout ça ?
Ce socle commun, sur lequel repose la solution globale, est la bibliothèque mathématique et statistique IMSL pour C/C++. Elle couvre un très large domaine de de fonctionnalités, tire profit des machines multi-cœur via OpenMP et est devenue un standard de l'industrie du fait de sa robustesse, de ses performances et de sa fiabilité
Alors on parle de Python, de modules complémentaires, de bibliothèque de calcul pour C/C++,…Comment faire cohabiter simplement et de manière sure tous ces composants ?
Dans la pratique, il n’est en effet pas toujours facile d’assembler soi-même les différents composants open-source Python entre eux : on doit les télécharger depuis différents sites, vérifier que les versions soient compatibles entre elles et la documentation est parfois de qualité inégale. De plus, aucun support technique n’est assuré.
L’environnement de prototypage PyIMSL Studio est supporté et entièrement documenté et a en partie été conçu pour pallier cette lacune lié à l’hétérogénéité des composants : un click sur la fenêtre de bienvenue de PyIMSL Studio suffit pour installer tout ce petit monde sur votre machine, en assurant que l’ensemble soit cohérent :
- Python
- NumPy – le standard de facto pour la manipulation de tableaux et l’algèbre matricielle en Python
- PyODBC – module pour l’accès aux bases de données sous Windows et Linux
- xlrd – module Python pour l’importation de données depuis un fichier Excel
- matplotlib/pylab – composants Python pour la visualisation
- IPython – un puissant interpréteur de lignes de commandes pour le développement et l’exploration interactive en Python
- Eclipse/PyDev – un EDI complet pour Python
- TkInter/WxPython – 2 toolkits très populaires pour la création d’IHM en Python
- IMSL C – la bibliothèque mathématique et statistique pour C/C++
- PyIMSL – la couche permettant d’appeler IMSL C depuis Python de manière transparente
- Une documentation exhaustive et détaillée de chacun des algorithmes et des APIs, avec exemples à l’appui
Ca y est, PyIMSL Studio est installé sur mon poste. On peut avoir un exemple simple de mise en œuvre ?
Bien sûr. Il nous faut donc commencer par la phase de prototypage en Python. Au choix, on peut créer un projet Python avec l’EDI Eclipse comme ci-dessous,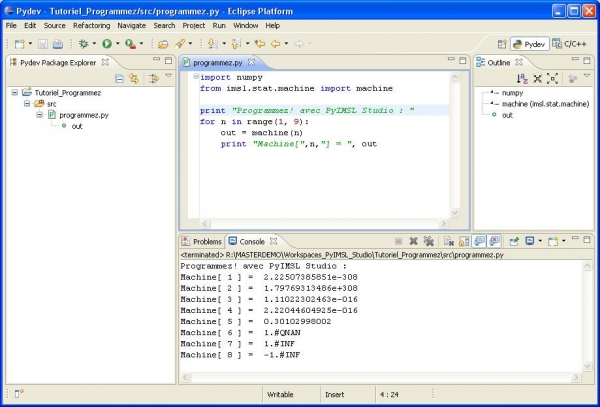
A présent, transposons ce code Python en langage C, pour notre application de production. Comme il l’a été annoncé au début de cet article, le point chaud est la partie calculatoire : comment la passer de Python vers C ? Notre code en C va-t-il rendre des résultats suffisamment proches ?
Le code C à produire est le suivant :
#include <stdio.h>
#include "imsl.h"
#define M 2
#define MEQ 1
#define N 2
void fcn(int n, double x[], int iact, double *result, int *ierr);
int main()
{
int ibtype = 0;
double *x;
static double xlb[N], xub[N];
xlb[0] = xlb[1] = imsl_d_machine(8); // -inf
xub[0] = xub[1] = imsl_d_machine(7); // +inf
// Appel au solveur d'IMSL C
x = imsl_d_constrained_nlp(fcn, M, MEQ, N, ibtype, xlb, xub, 0);
// Affichage de la solution
printf("La solution optimale est :\n");
printf("x1 = %15.13f x2 = %15.13f\n", x[0], x[1]);
}
void fcn(int n, double x[], int iact, double *result, int *ierr)
{
double tmp1, tmp2;
tmp1 = x[0] - 2.0e0;
tmp2 = x[1] - 1.0e0;
switch (iact) {
case 0:
*result = tmp1 * tmp1 + tmp2 * tmp2;
break;
case 1:
*result = x[0] - 2.0e0 * x[1] + 1.0e0;
break;
case 2:
*result = -(x[0]*x[0]) / 4.0e0 - x[1]*x[1] + 1.0e0;
break;
default: ;
break;
}
*ierr = 0;
return;
}
Il est très similaire dans son ensemble à son homologue Python, nous avons pris soin d’utiliser les mêmes noms de variables pour souligner cette similitude. Mais penchons-nous davantage sur la partie « solveur ».
En Python : x = constrainedNlp(fcn, m, meq, ibtype, xlb, xub)
En C : x = imsl_d_constrained_nlp(fcn, M, MEQ, N, ibtype, xlb, xub, 0);
On remarque que l’API est quasiment identique entre les 2 langages (noms de fonctions extrêmement proches, mêmes arguments, même ordre. Le langage C impose néanmoins de préciser le nombre de variables N et la fin de la liste des arguments par un 0. Le préfixe imsl_d_ indique par ailleurs qu’on appelle une fonction de la librairie IMSL C en double précision). De fait, il n’a pas été nécessaire :
- De recoder cet algorithme complexe ;
- De faire « coller » deux APIs totalement différentes, issues de 2 langages totalement différents.
Mais vérifions toutefois que notre code C fonctionne bien et qu’il rend des résultats suffisamment proches de ceux rendus par notre prototype. Après une compilation, une édition de liens et une exécution classiques, le verdict est sans appel :
La solution optimale est :
x1 = 0.8228756555323 x2 = 0.9114378277661
Appuyez sur une touche pour continuer...
Les résultats ne sont pas « proches » mais tout bonnement identiques !
Et si on faisait un petit bilan ?
Ce tutoriel nous a permis de montrer qu’avec l’environnement de prototypage et de mise en production PyIMSL Studio :
- Nous n’avons pas eu besoin de recoder la partie calculatoire de notre langage de prototypage (Python) vers C/C++ ;
- Nous nous sommes appuyés sur une librairie mathématique et statistique, IMSL, un standard de l’industrie depuis plus de 35 ans ;
- Nous obtenons les mêmes résultats numériques des 2 côtés, ce qui assure une parfaite cohérence entre notre prototype et notre application de production.
De plus, l’algorithme que nous avons utilisé est parallèle (repose sur la technologie OpenMP), ce qui lui permet de profiter des performances des machines multi-cœur, mais c’est une autre histoire…
Ajouter un commentaire