
Comprendre et synthétiser le langage naturel, reconnaître des visages… Incontestablement, l’Intelligence Artificielle (IA) est de nouveau tendance. Après des débuts marqués par l’imagination des futurologues et des écrivains de science-fiction, l’IA semble désormais à portée de main et les performances et exploits des systèmes cognitifs IBM Watson ou du programme intelligent AlphaGo de DeepMind sont clairement les prémices de son succès.
Souvent associé à ces exploits, le Deep Learning (apprentissage profond) ne finit pas de susciter l’enthousiasme des data scientists et promet de révolutionner la pratique du Machine Learning (apprentissage automatique ou statistique) et de la Data Science (science des données).
Avec l’augmentation de la puissance des ordinateurs et la profusion des données disponibles, le Machine Learning devient un composant important des projets Big Data et le Deep Learning se développe rapidement. Dans ce propos, nous allons tenter d’expliquer intuitivement le Machine Learning et le Deep Learning.
Du Machine Learning au Deep Learning
Le Machine Learning (ML) est une technique qui permet de rationaliser la prise de décision dans un environnement incertain, un environnement où il est très difficile d’expliciter les règles formelles expliquant les phénomènes d’intérêt. Dans une approche ML, l’acquisition de la connaissance se fait par la découverte des règles implicites dans les données brutes en suivant un processus itératif.
Prenons un exemple : Il est impossible de définir des règles qui permettent de déterminer de façon certaine qu’un e-mail est un spam ou pas. Dans ce cas, le Machine Learning est souvent utilisé pour apprendre ces règles à partir des données.
À chaque itération d’une modélisation de type Machine Learning, les data scientists procèdent à la préparation et au choix des variables prédictives, c’est-à-dire des données pertinentes pour créer/améliorer un modèle statistique. Cette activité humaine consiste en l’identification de la meilleure représentation des variables d’entrée : le data scientist choisit le formatage (ex : entier ou à virgule flottante), la bonne granularité, le niveau de discrétisation des variables continues, etc.
Le choix de la meilleure représentation des données est déterminant pour la qualité de la modélisation (« Garbage in, garbage out »), et implique des décisions subjectives qui font appel à l’expérience du data scientist, à son flair et parfois sa bonne fortune !
Le Deep Learning (DL) est un sous-ensemble du Machine Learning. Il s’appuie sur les réseaux de neurones artificiels. Le Deep Learning adresse la problématique d’identification de la meilleure représentation des données en utilisant le Machine Learning non seulement pour trouver le meilleur modèle qui associe les données d’entrée aux données de sortie mais aussi pour découvrir automatiquement la meilleure représentation des données d’entrée.
Un modèle DL stocke l’intelligence extraite sur plusieurs couches de représentation (neurones artificiels). Chaque couche de représentation est exprimée en fonction d’une autre couche plus primitive (voir illustration ci-dessous).
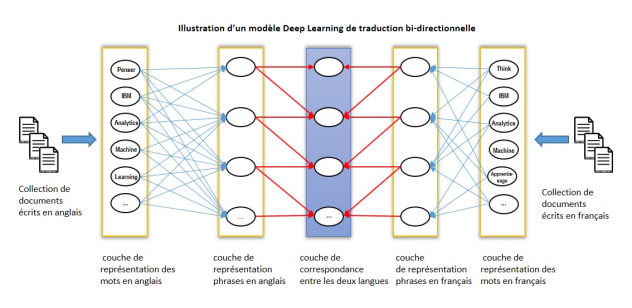
Deep Learning : Un modèle miracle ?
Le mécanisme d’empilement des couches décrit plus haut est le secret de la puissance du Deep Learning mais ce même mécanisme rend les modèles DL difficile à entraîner. La multiplication des couches, c’est-à-dire des connexions neuronales, et avec elles du nombre de paramètres à calibrer, nécessite une puissance de calcul considérable et des techniques très sophistiquées notamment de régularisation (problème d’over-fitting).
A ce jour, l’utilisation du Deep Learning reste limitée à des problématiques manipulant des données à topologie complexe -ce qui est souvent le cas des données non structurées (structure hiérarchique, dimensionnalité élevée, etc.).
Dans la pratique, le Deep Learning excelle dans les applications suivantes :
- La vision assistée par ordinateur (détection d’objets, génération d’images, etc.)
- La reconnaissance automatique de la parole
- Le traitement automatique de la langue (traduction, questions/réponses, etc.).
Deep Learning : Quel outillage ?
Les outils et les plateformes de construction de modèles Deep Learning restent largement orientés autour du développement. Plusieurs librairies Open Source fournissent les « briques de base » (architectures type, procédures d’optimisation, moteurs d’exécution sur GPU, etc.) pour la construction d’applications DL.
Voici quelques-unes des technologies Open Source pour créer des modèles Deep Learning :
- TensorFlow pour les programmeurs Python
- Caffe pour les développeurs C++ et Python
- Theano pour les programmeurs Python
- Deeplearning4j pour les développeurs Java/Spark (Scala et Python)
- Torch pour les programmeurs Lua.
En conclusion
Le Deep Learning permet de créer des modèles de Machine Learning plus performants, des systèmes capables de s’adapter automatiquement à la complexité structurelle des données manipulées. Toutefois, ces applications restent limitées à cause de la difficulté de mise en œuvre et des environnements de développement peu conviviaux.
Dans les années à venir, l’évolution des technologies et l’augmentation de la puissance de calcul accentueront le phénomène et permettront d’entraîner plus efficacement encore les réseaux de neurones profonds. Mais pour l’heure, les data scientists continuent d’utiliser massivement les modèles de Machine Learning traditionnels, plus aboutis et faciles à entraîner. Le miracle du Deep Learning reste encore à venir !
Zied Abidi, data scientist, IBM France
